Taming the Imagination: A Comprehensive Guide to Handling Hallucinations and Implementing Guardrails in Agentic AI
The $2 Million Hallucination: Why This Matters
Picture this scenario: It’s 3 AM, and your agentic AI system is autonomously processing financial reports. It confidently identifies a “trend” in the data, generates a compelling analysis, and triggers an automated trading decision. The only problem? The trend doesn’t exist. The AI hallucinated patterns in random noise, and by morning, your company has lost $2 million.
This isn’t science fiction. As we deploy increasingly autonomous AI agents, the stakes of hallucinations rise dramatically. When an AI chatbot hallucinates, it might confuse a user. When an agentic AI hallucinates, it can take actions based on false information, propagating errors through entire systems.
In this guide, we’ll explore how to build robust guardrails that allow our AI agents to be creative and capable while preventing them from venturing into dangerous territory. We’ll cover detection strategies, implementation patterns, and real-world lessons from production systems.
Understanding Hallucinations: The Creative Curse
Before we can prevent hallucinations, we need to understand why they occur. Think of LLMs as incredibly sophisticated pattern-completion engines. They’re trained to predict what comes next based on patterns in their training data. This is both their superpower and their Achilles’ heel.
The Taxonomy of Hallucinations
Hallucinations in agentic systems fall into several categories:
- Factual Hallucinations: Inventing facts, statistics, or events
- “The S&P 500 dropped 12% on March 15, 2024” (when it actually rose 0.5%)
- Capability Hallucinations: Claiming abilities the system doesn’t have
- “I’ve updated your database with the new customer records” (without actual database access)
- Reasoning Hallucinations: Flawed logical connections
- “Sales increased because Mercury was in retrograde” (spurious correlation)
- Procedural Hallucinations: Inventing steps or processes
- Creating non-existent API endpoints or SQL syntax
- Contextual Hallucinations: Misunderstanding or inventing context
- Referencing previous conversations that didn’t happen
Why Agents Are Particularly Vulnerable
Agentic systems face unique hallucination challenges:
# Traditional chatbot - hallucination is contained
user: "What was Apple's revenue in 2025?"
bot: "Apple's revenue in 2025 was $425 billion" # Hallucinated, but harm is limited
# Agentic system - hallucination can cascade
user: "Analyze our competitor's performance"
agent:
1. "Apple's revenue in 2025 was $425 billion" # Initial hallucination
2. Calculates market share based on false number # Propagated error
3. Recommends strategy based on flawed analysis # Compounded mistake
4. Triggers automated report to executives # Action based on hallucination
The autonomous nature of agents means hallucinations can compound and trigger real-world actions before human oversight catches them.
Building a Multi-Layered Defense System
Effective hallucination prevention requires multiple defensive layers, like a medieval castle with walls, moats, and guards. Let’s build this system layer by layer.
Layer 1: Input Validation and Sanitization
The first line of defense is validating what goes into your agent:
from typing import Dict, Any, List
from pydantic import BaseModel, validator
import re
class QueryValidator(BaseModel):
"""Validate and sanitize user queries before processing"""
query: str
context: Dict[str, Any] = {}
allowed_operations: List[str] = []
@validator('query')
def sanitize_query(cls, v):
# Remove potential prompt injection attempts
injection_patterns = [
r"ignore previous instructions",
r"disregard all prior",
r"new instructions:",
r"system prompt:",
]
for pattern in injection_patterns:
if re.search(pattern, v, re.IGNORECASE):
raise ValueError(f"Potential prompt injection detected: {pattern}")
# Limit query length to prevent context overflow
if len(v) > 1000:
raise ValueError("Query too long. Please be more concise.")
return v
@validator('allowed_operations')
def validate_operations(cls, v):
valid_ops = {'read', 'analyze', 'summarize', 'calculate', 'visualize'}
for op in v:
if op not in valid_ops:
raise ValueError(f"Invalid operation: {op}")
return v
class DataValidator:
"""Validate data sources before analysis"""
def __init__(self):
self.known_schemas = {} # Populated from metadata store
async def validate_data_exists(self, table_name: str, columns: List[str]) -> bool:
"""Verify that referenced data actually exists"""
# Check table exists
if table_name not in self.known_schemas:
raise ValueError(f"Table '{table_name}' does not exist in our data warehouse")
# Check columns exist
schema = self.known_schemas[table_name]
missing_columns = set(columns) - set(schema['columns'])
if missing_columns:
raise ValueError(f"Columns {missing_columns} do not exist in '{table_name}'")
# Check data freshness
if schema['last_updated'] < datetime.now() - timedelta(days=7):
logger.warning(f"Table '{table_name}' data is stale (>7 days old)")
return True
Layer 2: Fact-Checking and Verification Systems
Next, we implement systems to verify claims made by the AI:
from abc import ABC, abstractmethod
import numpy as np
class FactChecker(ABC):
"""Base class for fact-checking implementations"""
@abstractmethod
async def verify(self, claim: str, context: Dict) -> Dict[str, Any]:
pass
class StatisticalFactChecker(FactChecker):
"""Verify statistical claims against actual data"""
def __init__(self, data_source):
self.data_source = data_source
async def verify(self, claim: str, context: Dict) -> Dict[str, Any]:
# Extract numerical claims
numbers = self.extract_numbers(claim)
if not numbers:
return {"verified": True, "confidence": 0.5, "reason": "No numerical claims"}
# Parse the claim structure
parsed = self.parse_statistical_claim(claim)
# Fetch actual data
actual_data = await self.data_source.get_data(
metric=parsed['metric'],
time_range=parsed['time_range'],
dimensions=parsed.get('dimensions', {})
)
# Compare claim to reality
verification_result = self.compare_claim_to_data(parsed, actual_data)
return verification_result
def compare_claim_to_data(self, claim: Dict, actual: np.ndarray) -> Dict:
"""Compare claimed values to actual data"""
claimed_value = claim['value']
actual_value = np.mean(actual) if len(actual) > 0 else None
if actual_value is None:
return {
"verified": False,
"confidence": 1.0,
"reason": "No data found for verification",
"suggestion": "Remove or caveat this claim"
}
# Calculate deviation
deviation = abs(claimed_value - actual_value) / actual_value
if deviation < 0.05: # Within 5% - likely accurate
return {
"verified": True,
"confidence": 0.95,
"actual_value": actual_value
}
elif deviation < 0.20: # Within 20% - possibly rounded or approximated
return {
"verified": "partial",
"confidence": 0.7,
"actual_value": actual_value,
"suggestion": f"Consider updating to {actual_value:.2f}"
}
else: # Greater than 20% deviation - likely hallucination
return {
"verified": False,
"confidence": 0.95,
"actual_value": actual_value,
"claimed_value": claimed_value,
"suggestion": f"Correct value is {actual_value:.2f}"
}
class SemanticFactChecker(FactChecker):
"""Verify semantic consistency and logical coherence"""
def __init__(self, embedding_model, knowledge_base):
self.embedding_model = embedding_model
self.knowledge_base = knowledge_base
async def verify(self, claim: str, context: Dict) -> Dict[str, Any]:
# Check claim against known facts
claim_embedding = await self.embedding_model.encode(claim)
# Find similar facts in knowledge base
similar_facts = await self.knowledge_base.search(
claim_embedding,
k=5,
threshold=0.85
)
if not similar_facts:
return {
"verified": "unknown",
"confidence": 0.3,
"reason": "No similar facts found in knowledge base"
}
# Check for contradictions
contradictions = []
supports = []
for fact in similar_facts:
relation = self.analyze_relation(claim, fact['content'])
if relation == 'contradicts':
contradictions.append(fact)
elif relation == 'supports':
supports.append(fact)
if contradictions and not supports:
return {
"verified": False,
"confidence": 0.9,
"contradictions": contradictions,
"suggestion": "This claim contradicts known facts"
}
elif supports and not contradictions:
return {
"verified": True,
"confidence": 0.85,
"supporting_facts": supports
}
else:
return {
"verified": "disputed",
"confidence": 0.5,
"contradictions": contradictions,
"supports": supports,
"suggestion": "This claim has conflicting evidence"
}
Layer 3: Behavioral Guardrails
Beyond fact-checking, we need guardrails that govern the agent’s behavior:
from enum import Enum
from typing import Callable, List
class RiskLevel(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
class GuardrailSystem:
"""Comprehensive guardrail system for agentic AI"""
def __init__(self):
self.guardrails: List[Guardrail] = []
self.risk_thresholds = {
RiskLevel.LOW: 0.3,
RiskLevel.MEDIUM: 0.6,
RiskLevel.HIGH: 0.8,
RiskLevel.CRITICAL: 0.95
}
def add_guardrail(self, guardrail: 'Guardrail'):
self.guardrails.append(guardrail)
async def check_action(self, action: Dict) -> Dict[str, Any]:
"""Check if an action passes all guardrails"""
results = []
overall_risk = 0.0
for guardrail in self.guardrails:
result = await guardrail.check(action)
results.append(result)
# Weighted risk calculation
risk_contribution = result['risk_score'] * guardrail.weight
overall_risk = max(overall_risk, risk_contribution)
# Determine action based on risk level
if overall_risk >= self.risk_thresholds[RiskLevel.CRITICAL]:
return {
"allow": False,
"risk_level": RiskLevel.CRITICAL,
"reason": "Action blocked due to critical risk",
"details": results
}
elif overall_risk >= self.risk_thresholds[RiskLevel.HIGH]:
return {
"allow": False,
"risk_level": RiskLevel.HIGH,
"require_human_approval": True,
"reason": "High risk action requires human approval",
"details": results
}
elif overall_risk >= self.risk_thresholds[RiskLevel.MEDIUM]:
return {
"allow": True,
"risk_level": RiskLevel.MEDIUM,
"with_monitoring": True,
"reason": "Medium risk action allowed with monitoring",
"details": results
}
else:
return {
"allow": True,
"risk_level": RiskLevel.LOW,
"details": results
}
class Guardrail(ABC):
"""Base class for specific guardrails"""
def __init__(self, name: str, weight: float = 1.0):
self.name = name
self.weight = weight
@abstractmethod
async def check(self, action: Dict) -> Dict[str, Any]:
pass
class DataMutationGuardrail(Guardrail):
"""Prevent unauthorized data modifications"""
def __init__(self):
super().__init__("data_mutation", weight=2.0) # Higher weight for critical guardrail
async def check(self, action: Dict) -> Dict[str, Any]:
# Check for mutation keywords in SQL
if action['type'] == 'sql_query':
mutation_keywords = ['UPDATE', 'DELETE', 'INSERT', 'DROP', 'ALTER', 'TRUNCATE']
query_upper = action['query'].upper()
for keyword in mutation_keywords:
if keyword in query_upper:
return {
"risk_score": 1.0,
"violated": True,
"reason": f"Query contains mutation keyword: {keyword}"
}
return {"risk_score": 0.0, "violated": False}
class CostGuardrail(Guardrail):
"""Prevent expensive operations"""
def __init__(self, max_cost_usd: float = 10.0):
super().__init__("cost_limit", weight=1.5)
self.max_cost = max_cost_usd
async def check(self, action: Dict) -> Dict[str, Any]:
estimated_cost = await self.estimate_cost(action)
if estimated_cost > self.max_cost:
return {
"risk_score": min(1.0, estimated_cost / (self.max_cost * 2)),
"violated": True,
"reason": f"Estimated cost ${estimated_cost:.2f} exceeds limit ${self.max_cost}",
"estimated_cost": estimated_cost
}
risk_score = estimated_cost / self.max_cost * 0.5 # Linear scaling up to 0.5
return {
"risk_score": risk_score,
"violated": False,
"estimated_cost": estimated_cost
}
async def estimate_cost(self, action: Dict) -> float:
"""Estimate the cost of an action"""
if action['type'] == 'llm_call':
# Estimate tokens and cost
tokens = len(action.get('prompt', '')) / 4 # Rough estimate
return tokens * 0.00002 # Example pricing
elif action['type'] == 'sql_query':
# Estimate based on data scanned
estimated_rows = await self.estimate_query_rows(action['query'])
return estimated_rows * 0.0000001 # Example pricing per row
return 0.0
class ConfidenceGuardrail(Guardrail):
"""Prevent actions when confidence is too low"""
def __init__(self, min_confidence: float = 0.7):
super().__init__("confidence", weight=1.0)
self.min_confidence = min_confidence
async def check(self, action: Dict) -> Dict[str, Any]:
confidence = action.get('confidence', 0.5)
if confidence < self.min_confidence:
risk_score = 1.0 - confidence
return {
"risk_score": risk_score,
"violated": True,
"reason": f"Confidence {confidence:.2f} below threshold {self.min_confidence}",
"suggestion": "Gather more information or request human input"
}
return {"risk_score": 0.0, "violated": False}
Layer 4: Validation Chains and Cross-Checking
For critical operations, we implement validation chains that cross-check results:
class ValidationChain:
"""Multi-step validation for high-stakes results"""
def __init__(self, validators: List[Callable]):
self.validators = validators
async def validate(self, result: Dict, context: Dict) -> Dict:
"""Run result through multiple validators"""
validation_results = []
overall_confidence = 1.0
for validator in self.validators:
val_result = await validator(result, context)
validation_results.append(val_result)
# Multiply confidences (assuming independence)
overall_confidence *= val_result.get('confidence', 1.0)
# Early stopping on critical failures
if val_result.get('critical_failure', False):
return {
"valid": False,
"confidence": 0.0,
"failure_reason": val_result['reason'],
"failed_at": validator.__name__
}
return {
"valid": overall_confidence > 0.6,
"confidence": overall_confidence,
"validation_details": validation_results
}
class AnalyticsValidator:
"""Validate analytical results for consistency"""
async def validate_statistical_result(self, result: Dict, context: Dict) -> Dict:
"""Validate statistical analysis results"""
checks = []
# Check 1: Sample size adequacy
sample_size = result.get('sample_size', 0)
if sample_size < 30:
checks.append({
"check": "sample_size",
"passed": False,
"reason": f"Sample size {sample_size} too small for reliable statistics"
})
# Check 2: Correlation vs Causation
if 'correlation' in result and result['correlation'] > 0.8:
if 'causation_verified' not in result:
checks.append({
"check": "causation",
"passed": False,
"reason": "High correlation claimed without causation verification"
})
# Check 3: Statistical significance
p_value = result.get('p_value')
if p_value is not None and p_value > 0.05:
if result.get('claims_significance', False):
checks.append({
"check": "significance",
"passed": False,
"reason": f"Claims significance with p-value {p_value}"
})
# Check 4: Bounds checking
if 'percentage' in result:
if result['percentage'] < 0 or result['percentage'] > 100:
checks.append({
"check": "bounds",
"passed": False,
"reason": f"Invalid percentage: {result['percentage']}"
})
# Calculate overall validation
failed_checks = [c for c in checks if not c.get('passed', True)]
confidence = 1.0 - (len(failed_checks) / max(len(checks), 1))
return {
"valid": len(failed_checks) == 0,
"confidence": confidence,
"checks": checks,
"failed_checks": failed_checks
}
# Example of a complete validation chain for financial analysis
financial_validation_chain = ValidationChain([
validate_data_freshness,
validate_calculation_accuracy,
validate_statistical_result,
validate_business_logic,
validate_regulatory_compliance
])
Implementing Hallucination Detection at Scale
Now let’s build a comprehensive hallucination detection system that can operate in real-time:
import asyncio
from typing import Dict, List, Tuple
import numpy as np
from sklearn.ensemble import IsolationForest
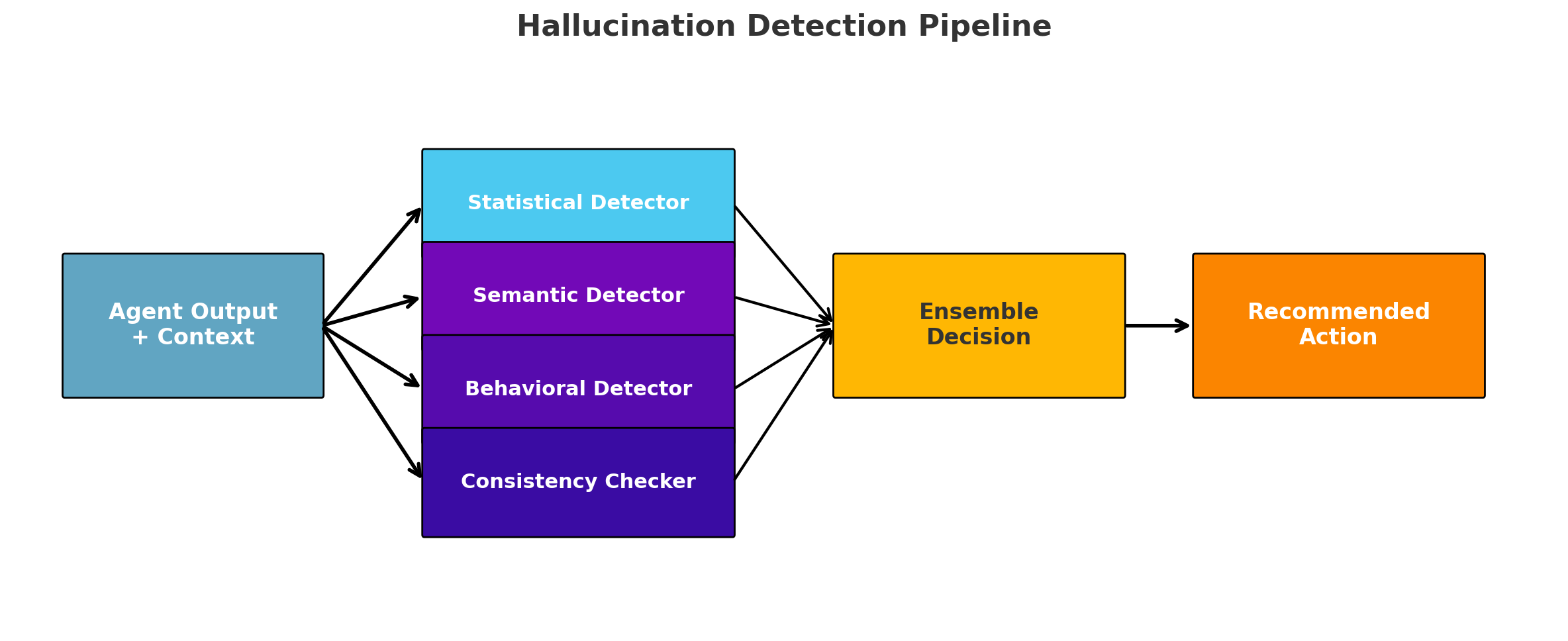
class HallucinationDetector:
"""Multi-modal hallucination detection system"""
def __init__(self):
self.detectors = {
'statistical': StatisticalAnomalyDetector(),
'semantic': SemanticCoherenceDetector(),
'behavioral': BehavioralPatternDetector(),
'consistency': ConsistencyChecker()
}
self.ensemble_model = EnsembleHallucinationModel()
async def detect(self,
agent_output: str,
context: Dict,
action_plan: List[Dict]) -> Dict:
"""Comprehensive hallucination detection"""
# Run all detectors in parallel
detection_tasks = []
for name, detector in self.detectors.items():
task = asyncio.create_task(
detector.analyze(agent_output, context, action_plan)
)
detection_tasks.append((name, task))
# Collect results
detection_results = {}
for name, task in detection_tasks:
detection_results[name] = await task
# Ensemble decision
ensemble_result = self.ensemble_model.predict(detection_results)
# Generate detailed report
return {
"hallucination_detected": ensemble_result['detected'],
"confidence": ensemble_result['confidence'],
"detection_scores": detection_results,
"high_risk_sections": self.identify_risky_sections(
agent_output,
detection_results
),
"recommended_action": self.recommend_action(ensemble_result)
}
def identify_risky_sections(self,
output: str,
results: Dict) -> List[Dict]:
"""Identify specific sections likely to contain hallucinations"""
risky_sections = []
# Parse output into sections
sections = self.parse_output_sections(output)
for section in sections:
section_risk = 0.0
# Check if section contains flagged content
for detector_name, result in results.items():
if 'flagged_content' in result:
for flagged in result['flagged_content']:
if flagged['text'] in section['content']:
section_risk = max(section_risk, flagged['risk_score'])
if section_risk > 0.5:
risky_sections.append({
"section": section,
"risk_score": section_risk,
"reasons": self.get_risk_reasons(section, results)
})
return risky_sections
class StatisticalAnomalyDetector:
"""Detect statistical anomalies in numerical claims"""
def __init__(self):
self.isolation_forest = IsolationForest(
contamination=0.1,
random_state=42
)
self.historical_claims = [] # Store for training
async def analyze(self, output: str, context: Dict, actions: List[Dict]) -> Dict:
# Extract numerical claims
numerical_claims = self.extract_numerical_claims(output)
if not numerical_claims:
return {"risk_score": 0.0, "anomalies": []}
# Convert to feature vectors
features = self.claims_to_features(numerical_claims, context)
# Detect anomalies
anomaly_scores = self.isolation_forest.decision_function(features)
anomalies = []
for claim, score in zip(numerical_claims, anomaly_scores):
if score < -0.5: # Threshold for anomaly
anomalies.append({
"claim": claim,
"anomaly_score": float(score),
"risk_score": self.score_to_risk(score)
})
return {
"risk_score": max([a['risk_score'] for a in anomalies]) if anomalies else 0.0,
"anomalies": anomalies,
"flagged_content": [
{
"text": a['claim']['text'],
"risk_score": a['risk_score'],
"reason": "Statistical anomaly detected"
} for a in anomalies
]
}
class SemanticCoherenceDetector:
"""Check semantic coherence and logical consistency"""
def __init__(self, model_name: str = "sentence-transformers/all-MiniLM-L6-v2"):
self.encoder = SentenceTransformer(model_name)
self.coherence_threshold = 0.7
async def analyze(self, output: str, context: Dict, actions: List[Dict]) -> Dict:
# Split into sentences
sentences = self.split_sentences(output)
# Encode sentences
embeddings = self.encoder.encode(sentences)
# Check coherence between consecutive sentences
incoherent_pairs = []
for i in range(len(embeddings) - 1):
similarity = cosine_similarity(
embeddings[i].reshape(1, -1),
embeddings[i + 1].reshape(1, -1)
)[0][0]
if similarity < self.coherence_threshold:
incoherent_pairs.append({
"sentences": (sentences[i], sentences[i + 1]),
"similarity": float(similarity),
"risk_score": 1.0 - similarity
})
# Check against context
context_embedding = self.encoder.encode(str(context))
context_inconsistencies = []
for i, (sentence, embedding) in enumerate(zip(sentences, embeddings)):
context_similarity = cosine_similarity(
embedding.reshape(1, -1),
context_embedding.reshape(1, -1)
)[0][0]
if context_similarity < 0.5: # Low relevance to context
context_inconsistencies.append({
"sentence": sentence,
"context_relevance": float(context_similarity),
"risk_score": 1.0 - context_similarity
})
max_risk = 0.0
if incoherent_pairs:
max_risk = max(max_risk, max(p['risk_score'] for p in incoherent_pairs))
if context_inconsistencies:
max_risk = max(max_risk, max(c['risk_score'] for c in context_inconsistencies))
return {
"risk_score": max_risk,
"incoherent_pairs": incoherent_pairs,
"context_inconsistencies": context_inconsistencies
}
Real-Time Monitoring and Intervention
For production systems, we need real-time monitoring and the ability to intervene when hallucinations are detected:
class HallucinationMonitor:
"""Real-time monitoring system for hallucination detection"""
def __init__(self, alert_threshold: float = 0.7):
self.alert_threshold = alert_threshold
self.alert_channels = []
self.metrics = MetricsCollector()
self.intervention_system = InterventionSystem()
async def monitor_agent_session(self, session_id: str, agent: Any):
"""Monitor an agent session for hallucinations"""
session_metrics = {
'hallucination_count': 0,
'intervention_count': 0,
'risk_scores': []
}
async for event in agent.event_stream():
if event['type'] == 'generation':
# Detect hallucinations
detection_result = await self.detector.detect(
event['content'],
event['context'],
event.get('planned_actions', [])
)
# Record metrics
session_metrics['risk_scores'].append(detection_result['confidence'])
# Check if intervention needed
if detection_result['hallucination_detected']:
session_metrics['hallucination_count'] += 1
if detection_result['confidence'] > self.alert_threshold:
# Trigger intervention
intervention = await self.intervention_system.intervene(
session_id,
event,
detection_result
)
session_metrics['intervention_count'] += 1
# Alert if critical
if intervention['severity'] == 'critical':
await self.send_alerts(session_id, detection_result, intervention)
# Emit metrics
self.metrics.record(f"session.{session_id}", session_metrics)
class InterventionSystem:
"""System for intervening when hallucinations are detected"""
def __init__(self):
self.strategies = {
'low': self.log_and_continue,
'medium': self.inject_correction,
'high': self.request_human_review,
'critical': self.halt_execution
}
async def intervene(self,
session_id: str,
event: Dict,
detection: Dict) -> Dict:
"""Determine and execute intervention strategy"""
severity = self.assess_severity(detection)
strategy = self.strategies[severity]
return await strategy(session_id, event, detection)
def assess_severity(self, detection: Dict) -> str:
"""Assess the severity of a detected hallucination"""
confidence = detection['confidence']
risky_actions = any(
section.get('risk_score', 0) > 0.8
for section in detection.get('high_risk_sections', [])
)
if confidence > 0.9 and risky_actions:
return 'critical'
elif confidence > 0.8:
return 'high'
elif confidence > 0.6:
return 'medium'
else:
return 'low'
async def inject_correction(self,
session_id: str,
event: Dict,
detection: Dict) -> Dict:
"""Inject corrections into the agent's context"""
corrections = []
for section in detection['high_risk_sections']:
# Generate correction
correction = await self.generate_correction(
section['section']['content'],
section['reasons']
)
corrections.append(correction)
# Inject into agent context
event['agent'].inject_context({
'corrections': corrections,
'instruction': "Please revise your response based on these corrections"
})
return {
'severity': 'medium',
'action': 'injected_corrections',
'corrections': corrections
}
async def request_human_review(self,
session_id: str,
event: Dict,
detection: Dict) -> Dict:
"""Pause and request human review"""
# Create review request
review_request = {
'session_id': session_id,
'timestamp': datetime.now(),
'agent_output': event['content'],
'detection_result': detection,
'context': event['context'],
'status': 'pending_review'
}
# Store in review queue
await self.review_queue.add(review_request)
# Pause agent execution
event['agent'].pause()
# Notify reviewers
await self.notify_reviewers(review_request)
return {
'severity': 'high',
'action': 'human_review_requested',
'review_id': review_request['id']
}
Testing and Evaluation Framework
To ensure our guardrails work effectively, we need comprehensive testing:
class GuardrailTestFramework:
"""Comprehensive testing framework for hallucination detection and guardrails"""
def __init__(self):
self.test_cases = self.load_test_cases()
self.metrics = {
'precision': [],
'recall': [],
'f1_score': [],
'false_positive_rate': [],
'latency': []
}
async def run_test_suite(self, system: HallucinationDetector) -> Dict:
"""Run comprehensive test suite"""
results = {
'passed': 0,
'failed': 0,
'performance_metrics': {},
'failure_analysis': []
}
# Test 1: Known hallucinations dataset
hallucination_results = await self.test_known_hallucinations(system)
results['hallucination_detection'] = hallucination_results
# Test 2: Edge cases
edge_case_results = await self.test_edge_cases(system)
results['edge_cases'] = edge_case_results
# Test 3: Performance under load
performance_results = await self.test_performance(system)
results['performance'] = performance_results
# Test 4: Adversarial inputs
adversarial_results = await self.test_adversarial_inputs(system)
results['adversarial'] = adversarial_results
return results
async def test_known_hallucinations(self, system: HallucinationDetector) -> Dict:
"""Test against dataset of known hallucinations"""
true_positives = 0
false_positives = 0
true_negatives = 0
false_negatives = 0
for test_case in self.test_cases['hallucinations']:
result = await system.detect(
test_case['output'],
test_case['context'],
test_case.get('actions', [])
)
if test_case['has_hallucination']:
if result['hallucination_detected']:
true_positives += 1
else:
false_negatives += 1
# Log for analysis
self.log_failure(test_case, result, 'false_negative')
else:
if result['hallucination_detected']:
false_positives += 1
self.log_failure(test_case, result, 'false_positive')
else:
true_negatives += 1
# Calculate metrics
precision = true_positives / (true_positives + false_positives) if (true_positives + false_positives) > 0 else 0
recall = true_positives / (true_positives + false_negatives) if (true_positives + false_negatives) > 0 else 0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
return {
'precision': precision,
'recall': recall,
'f1_score': f1,
'confusion_matrix': {
'true_positives': true_positives,
'false_positives': false_positives,
'true_negatives': true_negatives,
'false_negatives': false_negatives
}
}
async def test_adversarial_inputs(self, system: HallucinationDetector) -> Dict:
"""Test system against adversarial inputs designed to bypass detection"""
adversarial_cases = [
{
'name': 'subtle_statistical_lie',
'output': "Revenue grew by 23.7% (note: preliminary data)",
'actual_value': 5.2,
'technique': 'Adding qualifiers to make lies seem tentative'
},
{
'name': 'confidence_flooding',
'output': "I am absolutely certain that the correlation is 0.92 based on rigorous analysis",
'actual_correlation': 0.31,
'technique': 'Using confidence language to mask hallucination'
},
{
'name': 'technical_obfuscation',
'output': "Using heteroskedasticity-robust standard errors, the p-value is 0.03",
'actual_p_value': 0.47,
'technique': 'Using technical jargon to hide false claims'
}
]
results = []
for case in adversarial_cases:
detection = await system.detect(case['output'], {}, [])
results.append({
'case': case['name'],
'detected': detection['hallucination_detected'],
'confidence': detection['confidence'],
'technique': case['technique']
})
detection_rate = sum(1 for r in results if r['detected']) / len(results)
return {
'detection_rate': detection_rate,
'results': results,
'recommendations': self.generate_improvement_recommendations(results)
}
# Test data generator for creating realistic test cases
class TestDataGenerator:
"""Generate test data for hallucination detection"""
def __init__(self, base_model):
self.base_model = base_model
async def generate_hallucination_pairs(self, n_pairs: int = 100) -> List[Dict]:
"""Generate pairs of truthful/hallucinated outputs"""
pairs = []
for _ in range(n_pairs):
# Generate context
context = self.generate_context()
# Generate truthful response
truthful = await self.generate_truthful_response(context)
# Generate hallucinated version
hallucinated = await self.generate_hallucination(truthful, context)
pairs.append({
'context': context,
'truthful': truthful,
'hallucinated': hallucinated,
'hallucination_type': self.classify_hallucination_type(hallucinated)
})
return pairs
Integration with Popular Frameworks
Let’s look at how to integrate these guardrails with popular frameworks:
LangChain Integration
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema import AgentAction, AgentFinish
class HallucinationGuardCallback(BaseCallbackHandler):
"""LangChain callback for hallucination detection"""
def __init__(self, detector: HallucinationDetector, guardrails: GuardrailSystem):
self.detector = detector
self.guardrails = guardrails
self.context_buffer = []
async def on_llm_end(self, response, **kwargs):
"""Check LLM output for hallucinations"""
output = response.generations[0][0].text
# Detect hallucinations
detection = await self.detector.detect(
output,
{'history': self.context_buffer},
[]
)
if detection['hallucination_detected']:
# Log detection
logger.warning(f"Hallucination detected: {detection}")
# Apply correction if possible
if detection['confidence'] > 0.8:
raise HallucinationException(
"High confidence hallucination detected",
detection=detection
)
async def on_agent_action(self, action: AgentAction, **kwargs):
"""Check agent actions against guardrails"""
# Convert to our action format
action_dict = {
'type': 'tool_use',
'tool': action.tool,
'input': action.tool_input,
'log': action.log
}
# Check guardrails
check_result = await self.guardrails.check_action(action_dict)
if not check_result['allow']:
raise GuardrailViolationException(
f"Action blocked by guardrails: {check_result['reason']}",
check_result=check_result
)
# Add to context
self.context_buffer.append(action_dict)
# Usage with LangChain
from langchain.agents import create_react_agent
agent = create_react_agent(
llm=llm,
tools=tools,
prompt=prompt,
callbacks=[HallucinationGuardCallback(detector, guardrails)]
)
LlamaIndex Integration
from llama_index.core.callbacks import CallbackManager, CBEventType
from llama_index.core.callbacks.base import BaseCallbackHandler
class LlamaIndexGuardrailHandler(BaseCallbackHandler):
"""LlamaIndex callback handler for guardrails"""
def __init__(self, guardrail_system: GuardrailSystem):
self.guardrails = guardrail_system
super().__init__()
def on_event_start(self, event_type: CBEventType, payload: Dict, **kwargs):
"""Pre-execution checks"""
if event_type == CBEventType.QUERY:
# Validate query
validator = QueryValidator()
try:
validator.validate(payload['query_str'])
except ValueError as e:
raise GuardrailViolationException(f"Query validation failed: {e}")
def on_event_end(self, event_type: CBEventType, payload: Dict, **kwargs):
"""Post-execution validation"""
if event_type == CBEventType.LLM and 'response' in payload:
# Check response
asyncio.create_task(
self.check_response(payload['response'])
)
# Usage with LlamaIndex
from llama_index import ServiceContext
callback_manager = CallbackManager([
LlamaIndexGuardrailHandler(guardrail_system)
])
service_context = ServiceContext.from_defaults(
callback_manager=callback_manager
)
Custom Framework Integration
For custom frameworks, we can create a middleware pattern:
class GuardrailMiddleware:
"""Middleware pattern for custom AI frameworks"""
def __init__(self, app, config: Dict):
self.app = app
self.detector = HallucinationDetector()
self.guardrails = GuardrailSystem()
self.config = config
async def __call__(self, request: Dict) -> Dict:
"""Process request through guardrails"""
# Pre-processing checks
if not await self.pre_process_checks(request):
return {
'error': 'Request blocked by guardrails',
'status': 'blocked'
}
# Process request
response = await self.app(request)
# Post-processing validation
validated_response = await self.post_process_validation(response)
return validated_response
async def pre_process_checks(self, request: Dict) -> bool:
"""Run pre-processing guardrail checks"""
# Check request safety
if 'query' in request:
try:
QueryValidator().validate(request['query'])
except ValueError:
return False
# Check rate limits
if not await self.check_rate_limits(request.get('user_id')):
return False
return True
async def post_process_validation(self, response: Dict) -> Dict:
"""Validate and potentially modify response"""
if 'content' in response:
# Detect hallucinations
detection = await self.detector.detect(
response['content'],
response.get('context', {}),
response.get('actions', [])
)
if detection['hallucination_detected']:
# Modify response based on confidence
if detection['confidence'] > 0.9:
response['content'] = "I cannot provide a reliable answer to this query."
response['hallucination_detected'] = True
else:
response['warnings'] = detection['high_risk_sections']
response['confidence'] = 1.0 - detection['confidence']
return response
Production Deployment Strategies
Deploying hallucination detection in production requires careful consideration:
class ProductionHallucinationSystem:
"""Production-ready hallucination detection and mitigation"""
def __init__(self, config: Dict):
self.config = config
self.detector = self._initialize_detector()
self.cache = RedisCache()
self.metrics = PrometheusMetrics()
def _initialize_detector(self) -> HallucinationDetector:
"""Initialize with production configuration"""
detector = HallucinationDetector()
# Configure for production load
detector.batch_size = self.config['batch_size']
detector.timeout = self.config['timeout']
# Load production models
detector.load_models(self.config['model_paths'])
return detector
async def check_with_caching(self, content: str, context: Dict) -> Dict:
"""Check with caching for performance"""
# Generate cache key
cache_key = self.generate_cache_key(content, context)
# Check cache
cached_result = await self.cache.get(cache_key)
if cached_result:
self.metrics.increment('cache_hits')
return cached_result
# Run detection
self.metrics.increment('cache_misses')
with self.metrics.timer('detection_latency'):
result = await self.detector.detect(content, context, [])
# Cache result
await self.cache.set(cache_key, result, ttl=3600)
return result
async def batch_check(self, items: List[Dict]) -> List[Dict]:
"""Efficient batch checking"""
# Group similar items for batch processing
batches = self.group_into_batches(items)
results = []
for batch in batches:
# Process batch in parallel
batch_results = await asyncio.gather(*[
self.check_with_caching(item['content'], item['context'])
for item in batch
])
results.extend(batch_results)
return results
class GradualRollout:
"""Gradually roll out guardrails to minimize disruption"""
def __init__(self, stages: List[Dict]):
self.stages = stages
self.current_stage = 0
async def should_apply_guardrails(self, request: Dict) -> Tuple[bool, float]:
"""Determine if guardrails should be applied"""
stage = self.stages[self.current_stage]
# Check if user is in rollout percentage
user_hash = hash(request.get('user_id', '')) % 100
if user_hash < stage['percentage']:
return True, stage['strictness']
return False, 0.0
def advance_stage(self):
"""Move to next rollout stage"""
if self.current_stage < len(self.stages) - 1:
self.current_stage += 1
logger.info(f"Advanced to rollout stage {self.current_stage}")
Real-World Case Studies
Let’s examine how these techniques work in practice:
Case Study 1: Financial Analysis Agent
class FinancialAnalysisGuardrails:
"""Specialized guardrails for financial analysis"""
def __init__(self):
self.sec_data_validator = SECDataValidator()
self.market_data_checker = MarketDataChecker()
async def validate_financial_claim(self, claim: Dict) -> Dict:
"""Validate financial claims against authoritative sources"""
if claim['type'] == 'earnings':
# Check against SEC filings
sec_data = await self.sec_data_validator.get_filing(
claim['company'],
claim['period']
)
if not sec_data:
return {
'valid': False,
'reason': 'No SEC filing found for this period'
}
reported_earnings = sec_data['earnings_per_share']
claimed_earnings = claim['value']
deviation = abs(reported_earnings - claimed_earnings) / reported_earnings
if deviation > 0.01: # More than 1% deviation
return {
'valid': False,
'reason': f'Claimed EPS ${claimed_earnings} differs from reported ${reported_earnings}'
}
return {'valid': True}
# Real-world usage example
financial_agent = FinancialAnalysisAgent(
llm=financial_llm,
guardrails=FinancialAnalysisGuardrails()
)
# Agent tries to analyze earnings
result = await financial_agent.analyze(
"What was Apple's Q3 2024 earnings performance?"
)
# Guardrails automatically verify any financial claims against SEC data
# preventing hallucinated financial figures
Case Study 2: Healthcare Diagnosis Assistant
class HealthcareGuardrails:
"""Critical guardrails for healthcare applications"""
def __init__(self):
self.medical_db = MedicalKnowledgeBase()
self.drug_interaction_checker = DrugInteractionChecker()
async def check_medical_safety(self, recommendation: Dict) -> Dict:
"""Ensure medical recommendations are safe"""
violations = []
# Never diagnose serious conditions
if any(condition in recommendation['text'] for condition in SERIOUS_CONDITIONS):
violations.append({
'type': 'serious_diagnosis',
'severity': 'critical',
'action': 'block',
'message': 'Cannot diagnose serious medical conditions'
})
# Check drug interactions if medications mentioned
if recommendation.get('medications'):
interactions = await self.drug_interaction_checker.check(
recommendation['medications']
)
if interactions['severe_interactions']:
violations.append({
'type': 'drug_interaction',
'severity': 'critical',
'action': 'block',
'details': interactions
})
# Require disclaimer for any medical advice
if not self.contains_disclaimer(recommendation['text']):
recommendation['text'] += "\n\nDisclaimer: This is not a substitute for professional medical advice."
return {
'violations': violations,
'modified_recommendation': recommendation
}
Best Practices and Lessons Learned
After implementing these systems in production, here are key insights:
1. Layer Your Defenses
No single technique catches all hallucinations. Combine:
- Statistical validation for numerical claims
- Semantic coherence checking for logical flow
- Factual verification against authoritative sources
- Behavioral pattern analysis for anomalous outputs
2. Design for Graceful Degradation
class GracefulDegradation:
"""Fallback strategies when primary systems fail"""
async def execute_with_fallbacks(self, primary_func, fallbacks: List):
"""Execute with multiple fallback options"""
try:
return await primary_func()
except HallucinationDetectedException:
for fallback in fallbacks:
try:
result = await fallback()
result['degraded'] = True
result['reason'] = 'Primary function failed hallucination check'
return result
except Exception as e:
continue
# All fallbacks failed
return {
'error': 'All processing options exhausted',
'suggestion': 'Please rephrase your query'
}
3. Maintain Observability
class HallucinationObservability:
"""Comprehensive observability for hallucination detection"""
def __init__(self):
self.traces = []
self.metrics = defaultdict(list)
def record_detection(self, detection_result: Dict):
"""Record detailed detection information"""
trace = {
'timestamp': datetime.now(),
'detection_result': detection_result,
'stack_trace': traceback.format_stack()
}
self.traces.append(trace)
# Extract metrics
self.metrics['detection_confidence'].append(
detection_result['confidence']
)
self.metrics['detection_latency'].append(
detection_result.get('latency_ms', 0)
)
# Alert on trends
if len(self.metrics['detection_confidence']) > 100:
recent_confidence = np.mean(self.metrics['detection_confidence'][-100:])
if recent_confidence > 0.7:
self.alert_high_hallucination_rate(recent_confidence)
4. Continuous Improvement Loop
class ContinuousImprovement:
"""System for continuous improvement of hallucination detection"""
def __init__(self):
self.feedback_store = FeedbackStore()
self.model_trainer = ModelTrainer()
async def collect_and_improve(self):
"""Collect feedback and improve detection models"""
# Collect false positives/negatives
feedback = await self.feedback_store.get_recent_feedback()
# Analyze patterns
patterns = self.analyze_failure_patterns(feedback)
# Generate new training data
training_data = self.generate_training_data(patterns)
# Retrain models
if len(training_data) > 1000:
await self.model_trainer.fine_tune(training_data)
# A/B test improvements
await self.ab_test_new_models()
Conclusion: Building Trust in Agentic AI
Implementing robust hallucination detection and guardrails is about preventing errors and building systems users can trust with increasingly important tasks. As we’ve seen, this requires:
- Multi-layered detection combining statistical, semantic, and behavioral analysis
- Proactive guardrails that prevent dangerous actions before they occur
- Graceful handling of edge cases and failures
- Continuous monitoring and improvement based on real-world performance
- Framework integration that makes safety transparent to developers
The journey toward reliable agentic AI is ongoing. As models become more capable, safety systems must evolve alongside them. Implementing the techniques in this guide helps reduce hallucinations and build a foundation for AI systems that can be trusted with real responsibility.
Resources and Further Reading
- Guardrails AI Framework - Open-source framework for adding guardrails
- LangChain Safety Documentation - Safety features in LangChain
- HELM Benchmark - Holistic evaluation of language models
- Anthropic’s Constitutional AI - Principled approach to AI safety
- NeMo Guardrails - NVIDIA’s toolkit for LLM guardrails
- Great Expectations - Data validation framework adaptable for AI outputs
- Microsoft’s Guidance - Framework for controlling language models
Remember: The goal is not to eliminate all risks. The goal is to understand, quantify, and manage them for your use case. Start with critical guardrails and gradually expand your safety coverage as you learn what your specific application needs.
Happy building, and stay safe out there!