Lead Architect & Developer | May 2022 - July 2022
Building EventFly: Our Journey to Creating an Event Management Platform with Microservices
Introduction
Hello everyone! I’m excited to share our journey of building EventFly, a comprehensive event management platform. We created this system as part of our Software Development Lab course in Level 4, Term 1 at Bangladesh University of Engineering and Technology (BUET). Our small team of just six members had only two months to complete this ambitious project. As the lead architect, I handled backend development, DevOps responsibilities, and the overall system architecture.
What Is EventFly?
EventFly helps people create and manage events of all sizes. We designed it to be a complete solution that handles everything from event creation to participant engagement. An organizer can set up an event, sell tickets, send announcements, and collect feedback - all in one platform.
Features We Built
Our platform includes features that solve real problems for event organizers:
- Event Creation: Organizers can create events with detailed information including name, description, location, and time
- Staff Management: Organizers can add team members and assign specific roles with customized permissions
- Ticketing System: Create different ticket types with varying prices and access levels
- Participant Registration: Easy registration process for attendees with profile management
- Interactive Feed: Create posts, polls, and quizzes to engage with participants before, during, and after events
- Feedback Collection: Gather ratings and comments from attendees after events
- Analytics Dashboard: View attendance statistics, ticket sales, and engagement metrics
- Smart Recommendations: Participants receive personalized event suggestions based on location and interests
- Secure Payments: Process ticket purchases and subscription payments with Stripe integration
Our Team Structure
Our team of six had clear roles that aligned with our architecture:
- 2 Frontend Developers: Focused exclusively on building our Next.js-based interfaces
- 3 Backend Developers: Worked on service implementation and database management
- 1 Architect (me): Handled backend development, DevOps setup, and overall architecture design
This small team size influenced many of our architectural decisions, as we needed an approach that would maximize our productivity.
Why We Chose Microservices
Choosing between a monolithic architecture and microservices was our first major decision. Let me explain why we went with microservices in simple terms.
The Decision Process
A monolith is like a single large apartment where everything is connected. Microservices are more like a housing complex with separate units that communicate with each other.
The Monolith Option:
- Would be faster to set up initially
- Would require less operational complexity
- Might be simpler for our small team
The Microservices Option:
- Would allow team members to work independently
- Would let us use different technologies where appropriate
- Would make the system more resilient to failures
- Would be easier to extend and maintain long-term
We chose microservices for several practical reasons:
-
Team Autonomy: Even with only six members, we wanted developers to work on separate services without stepping on each other’s toes. This was crucial for our tight two-month timeline.
-
Technology Requirements: Our analytics features needed Python for machine learning capabilities, while our core services were built with Node.js. Microservices allowed this mixed technology approach.
-
Learning Opportunity: As a university project, we wanted to gain experience with modern architectural patterns used in industry.
-
Feature Independence: Some features like payments needed to be extremely reliable, while others like the newsfeed could tolerate occasional issues. Microservices let us apply different reliability standards to different components.
I remember explaining it to our professor: “With only two months and six people, we need an architecture that lets everyone work productively in parallel. Microservices will let us divide the work cleanly while learning valuable industry practices.”
Domain-Driven Design: Making Sense of Complexity
We embraced Domain-Driven Design (DDD) principles to guide our microservices architecture. This approach helped us create services that aligned with business capabilities rather than technical concerns.
Event Storming Sessions
We began with event storming sessions where we mapped out the entire business domain on a whiteboard using colorful sticky notes:
- Orange notes for domain events (“Event Created,” “Ticket Purchased”)
- Blue notes for commands (“Create Event,” “Purchase Ticket”)
- Green notes for aggregates (“Event,” “Organization,” “Participant”)
- Yellow notes for queries (“Find Events Near Me,” “Get Event Details”)
This visual exercise helped us identify natural boundaries in our system. We could clearly see which operations and data belonged together, and which were separate concerns.
Bounded Contexts
From our event storming sessions, we identified distinct bounded contexts - areas of the system with their own consistent terminology and rules. These became our microservices:
- Authentication & Identity: Handling user accounts and authentication
- Organization Management: Managing organizations and their staff
- Event Management: Handling event creation and details
- Participant Engagement: Managing interactive content and feeds
- Registration: Processing participant sign-ups and check-ins
- Payment Processing: Handling financial transactions
- Analytics & Recommendations: Providing insights and suggestions
Each bounded context had its own ubiquitous language - a consistent set of terms used by both developers and business stakeholders. For example, in the Event Management context, we used terms like “organizer,” “venue,” and “schedule.” In the Payment context, we used “transaction,” “refund,” and “payment method.”
For more on Domain-Driven Design, I recommend the article “Domain-Driven Design: Tackling Complexity in the Heart of Software” by Martin Fowler, which greatly influenced our approach.
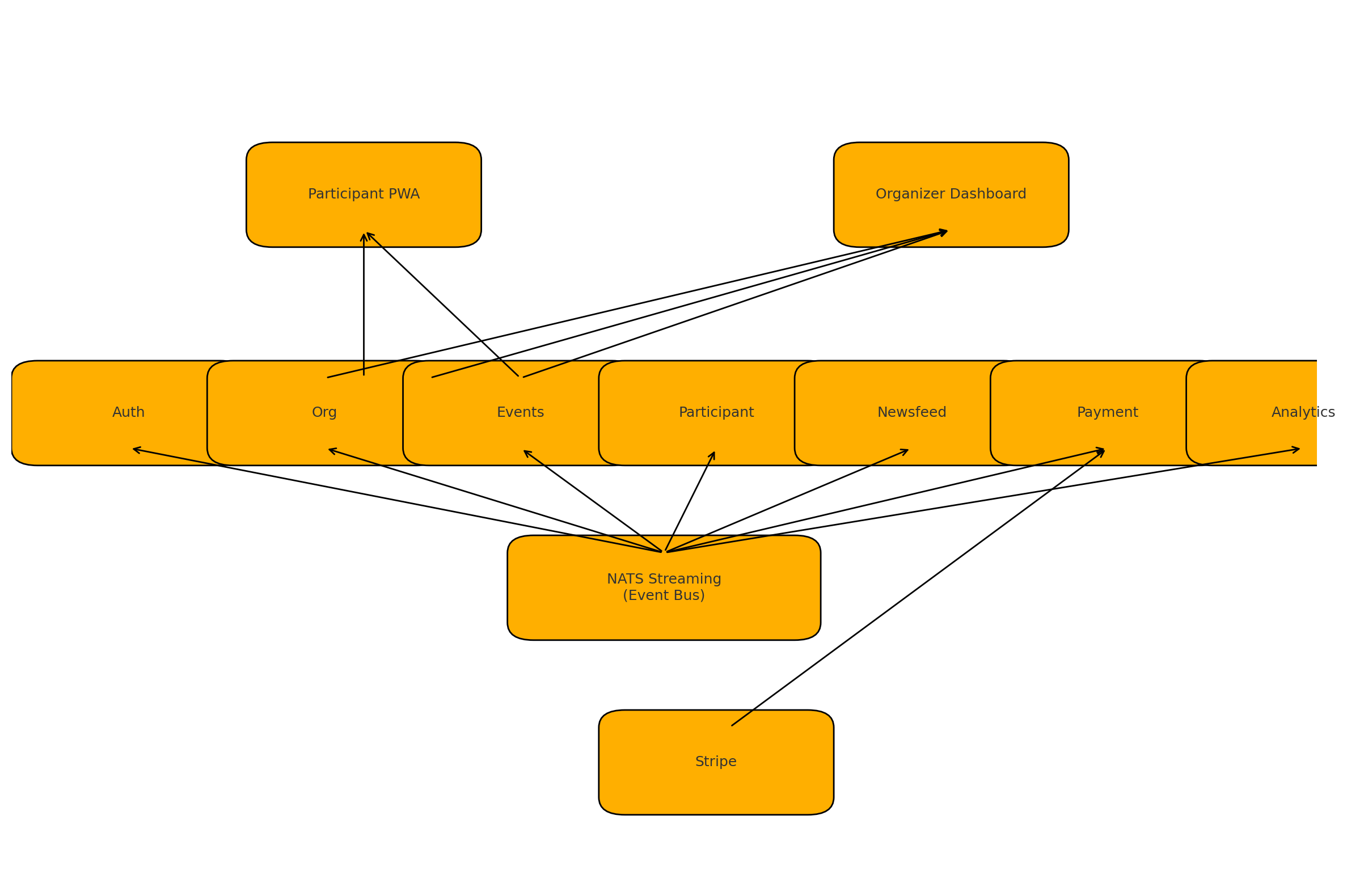
Our Architecture - The Seven Services
Based on our DDD analysis, we divided EventFly into seven core services:
- Auth Service: Handles user authentication, authorization, and profile management
- Organization Service: Manages organization profiles, staff, and subscription packages
- Events Service: Stores event details, schedules, and manages event-specific staff
- Newsfeed Service: Manages posts, polls, quizzes, and other interactive content
- Participant Service: Handles attendee registration, check-ins, and feedback
- Payment Service: Processes ticket purchases and subscription payments
- Analytics Service: Provides recommendation algorithms and event insights
Each service had its own MongoDB database and communicated through a NATS Streaming server for asynchronous messaging. For synchronous communication, services exposed REST APIs.
Our frontend consisted of two Next.js applications:
- An organizer portal for event management
- A participant-facing app for discovering and attending events
Technical Implementation Details
Let me share some of the more interesting technical aspects of our implementation.
Deployment Architecture
Our deployment architecture was designed for scalability and resilience, utilizing Kubernetes for orchestration:
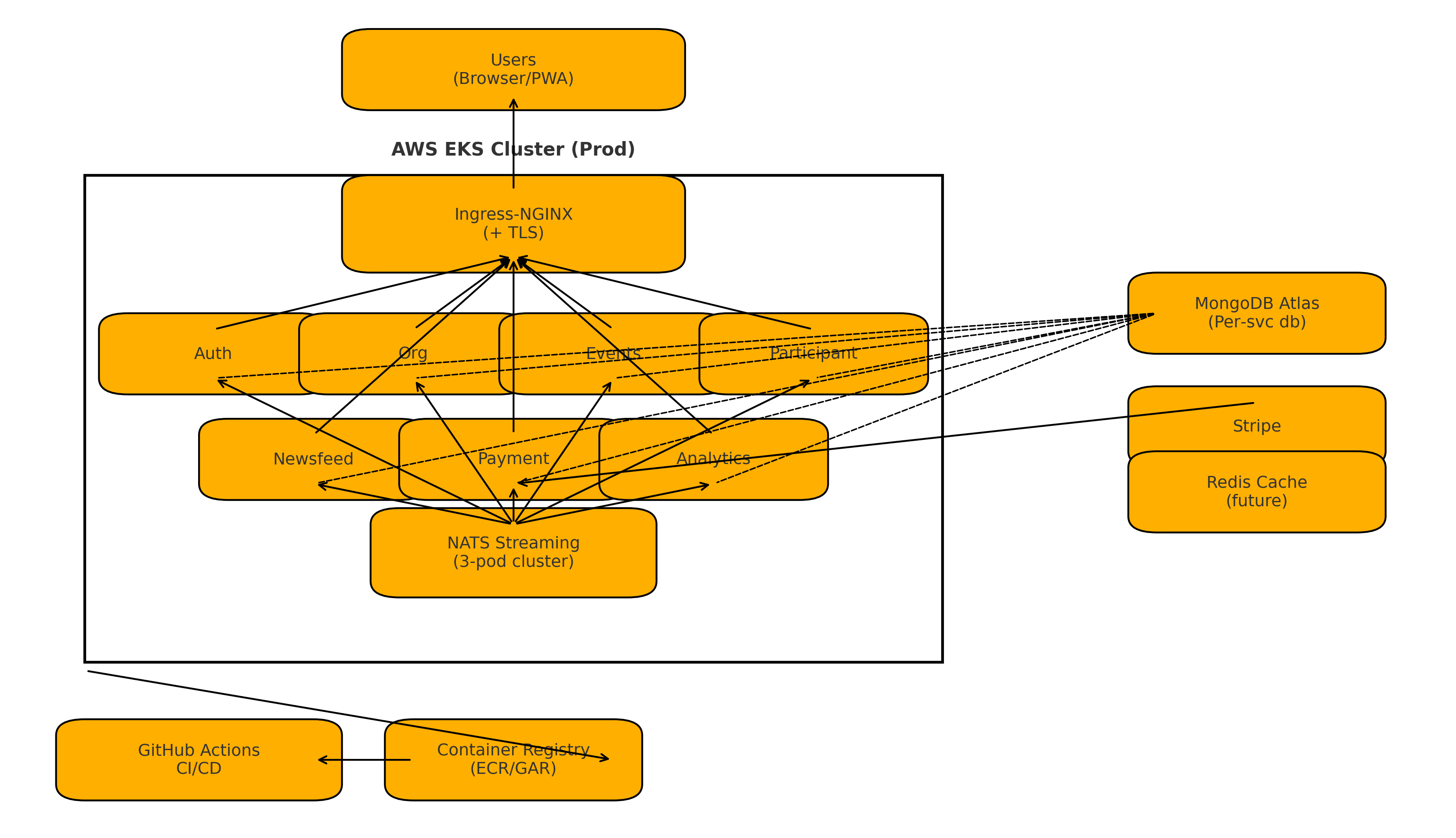
Service Independence with Docker
We containerized each service using Docker. This gave us several benefits:
- Each service could be developed and deployed independently
- We could use different Node.js versions or libraries if needed
- New team members could start developing quickly with a consistent environment
- Services could be scaled individually based on load
Our docker-compose.yaml file defined the entire development environment, making it easy for any team member to run the complete system locally:
version: "3.9"
services:
nats_server:
image: nats-streaming
ports:
- "4222:4222"
auth:
build: ./auth
ports:
- "3000:3000"
environment:
- NATS_CLIENT_ID=auth
org:
build: ./org
ports:
- "3001:3000"
environment:
- NATS_CLIENT_ID=org
# Other services followed the same pattern
For a deeper understanding of containerization in microservices, the article “Production-Ready Docker Packaging” was very helpful to us.
Event-Driven Communication
We used an event-driven architecture for communication between services. When something important happened in one service, it published an event to NATS Streaming. Other services subscribed to relevant events and updated their own data accordingly.
For example, when a new event was created:
// In the Organization service
natsWrapper.client.publish('event:created', JSON.stringify({
id: event.id,
name: event.name,
organizer: event.organizer,
start_date: event.start_date,
end_date: event.end_date,
// other event properties
}));
// In the Events service
class EventCreatedListener extends Listener {
subject = 'event:created';
queueGroupName = 'event-created-event';
async onMessage(data, msg) {
console.log('Event Created! Data: ', data);
const event = Event.build({
name: data.name,
organizer: data.organizer,
// other properties
});
await event.save();
msg.ack();
}
}
This pattern helped us maintain loose coupling between services while ensuring data consistency across the system. The article “Event-Driven Architecture” by Martin Fowler provided excellent guidance in this area.
Python Integration for Analytics
One unique challenge was integrating Python-based machine learning algorithms with our Node.js services. We solved this by creating a hybrid service:
// In our Analytics service (Node.js)
const runPythonScript = (events, participantData) => {
const python = spawn('python3', [
'recommender.py',
JSON.stringify(events),
JSON.stringify(participantData)
]);
python.stdout.on('data', (data) => {
const recommendations = JSON.parse(data.toString());
return recommendations;
});
};
This approach allowed us to use Python’s rich data science libraries while maintaining consistency with our overall architecture.
CI/CD Pipeline: Automating Our Workflow
With a microservices architecture, having a solid CI/CD pipeline was essential. We set up GitHub Actions to automate our development workflow:
- Continuous Integration:
- Automated testing for each service when code was pushed
- Linting checks to maintain code quality
- Build verification to catch issues early
- Continuous Deployment:
- Automatic Docker image building for updated services
- Deployment to our development environment for feature branches
- Production deployment when changes were merged to main
Here’s a simplified example of our GitHub Actions workflow:
name: Deploy to Dev Environment
on:
push:
branches: [ feature/* ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- run: cd auth && npm install && npm test
# Similar steps for other changed services
build-and-deploy:
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Build Docker images
run: docker-compose build
- name: Push to registry
run: docker-compose push
- name: Deploy to Dev
run: kubectl apply -f infra/k8s/dev
This automation was crucial for our small team, as it freed us from manual deployment tasks and provided consistent quality checks. The article “CI/CD for Microservices on Kubernetes” helped us design this workflow.
Challenges We Faced With Our Small Team
Building a microservices system with just six people in two months presented unique challenges:
Balancing Team Size with Service Count
With seven services and only six team members, we had to be strategic. We prioritized:
- Core services (Auth, Events, Participant) got full-time attention
- Less critical services were developed part-time
- Some team members worked across multiple services
The lesson: Even with microservices, you need to balance service count with team capacity. We could have combined some services, but the clear boundaries were worth the extra effort.
Data Consistency Without Complex Mechanisms
With separate databases for each service, keeping data consistent was challenging. We couldn’t implement complex distributed transaction systems in our timeframe.
Our solution was a pragmatic approach to eventual consistency:
- Use event messages to propagate changes
- Include timestamps with all data
- Build reconciliation processes for critical data
- Accept that some non-critical data might be temporarily out of sync
I explained it to our team using a simple analogy: “It’s like how universities handle student information. The registrar, accounting, and library departments all have your data. When you change your address, it might take time for all departments to update their records.”
For more insights on managing data in distributed systems, “Data Consistency in Microservices Architecture” was invaluable.
Limited DevOps Resources
With only one person (me) handling DevOps, we needed to keep operations simple but effective.
We implemented:
- Automated deployment with GitHub Actions
- Basic monitoring using Prometheus and Grafana
- Centralized logging with ELK Stack
- Simple health check endpoints for each service
The key was automation. Everything from testing to deployment was automated, allowing our small team to focus on development rather than operations.
How Microservices Helped Our Team Work Better
Despite the challenges, microservices significantly improved our team’s productivity:
Independent Development
With our team split between frontend and backend, microservices allowed everyone to work productively:
- Frontend developers could work with mocked backend responses
- Backend developers could work on different services simultaneously
- Services could be deployed independently as they were completed
This independence was crucial for meeting our two-month deadline. We didn’t need to coordinate deployments or worry about breaking each other’s code.
Technology Flexibility
Microservices allowed us to use different technologies where appropriate:
- Core services used Node.js with Express
- Analytics used Node.js to invoke Python scripts
- Frontend used Next.js for server-side rendering
- Infrastructure as Code used Terraform
This flexibility let us choose the right tool for each job rather than forcing a one-size-fits-all approach.
Clear Ownership
Each service had a primary owner who was responsible for its design and implementation. This created:
- Deeper expertise in specific areas
- Pride in ownership that motivated quality work
- Faster decision-making
- More innovative solutions
For example, our analytics specialist became an expert in recommendation algorithms, while our payment specialist mastered secure transaction processing.
My Role as Lead Architect
As the sole architect in our six-person team, I had to balance hands-on development with architectural guidance:
Setting the Foundation
I created:
- A reference architecture that all services followed
- Standardized patterns for common problems
- Infrastructure as Code templates for deployment
- Guidelines for API design and event schemas
These standards gave the team a consistent starting point while allowing flexibility for specific service needs.
Hands-On Technical Leadership
Unlike in larger teams where an architect might focus exclusively on design, I was both architect and developer:
- Implemented the core authentication service myself
- Set up the CI/CD pipeline
- Created shared libraries for common functionality
- Rotated between services to help other developers
This hands-on approach let me identify and address cross-cutting concerns early. When I noticed teams implementing similar logging patterns differently, I created a shared logging library that standardized the approach across services.
Knowledge Sharing
In our small team, knowledge sharing was important. I established:
- Weekly architecture review sessions
- Pair programming for complex features
- Comprehensive documentation requirements
- Cross-service code reviews
These practices ensured that although each person had primary ownership of specific services, everyone understood the overall system.
Lessons Learned in Our University Project
Building EventFly as part of our university course provided unique insights:
-
Right-sized services: We initially planned nine services but realized that was too many for our team size. Combining some related functionality into seven services was more manageable.
-
Documentation is essential: With different people owning different services, good documentation became our shared language. Services with thorough documentation were integrated more easily.
-
Start with infrastructure: Setting up a solid development environment and CI/CD pipeline early saved countless hours later. Automation is worth the initial investment.
-
Domain-driven design works: Taking time to understand the business domain before writing code led to more intuitive service boundaries and better system design.
-
Balance theory and pragmatism: While we followed microservices best practices where possible, we also made pragmatic compromises when needed for our timeline.
The Academic Context
Completing EventFly as part of our Software Development Lab at BUET provided both advantages and constraints:
Advantages:
- Access to professors with expertise in distributed systems
- Freedom to experiment with cutting-edge architecture
- Opportunity to apply theoretical concepts in a practical project
Constraints:
- The strict two-month timeline
- Limited team size of just six members
- Balancing this project with other coursework
- Limited budget for infrastructure
Despite these constraints, we built a working system that demonstrated both technical excellence and practical usability. Our professors were particularly impressed with how we applied microservices concepts in a real-world project with such a small team.
Conclusion
Building EventFly using microservices was the right choice for our specific context. The architecture allowed our small team to:
- Work independently on different parts of the system
- Use appropriate technologies for each component
- Create clear boundaries between different functionality
- Meet our ambitious two-month deadline
For small teams considering microservices, I recommend:
- Start with domain-driven design to identify service boundaries
- Invest early in CI/CD automation
- Use simple, pragmatic approaches to cross-cutting concerns
- Balance service count with team capacity
- Prioritize clear documentation and knowledge sharing
Our experience shows that microservices aren’t just for large teams. With careful planning and the right tools, even a small team of six university students can successfully implement a microservices architecture in a tight timeframe.
Further Reading
If you’re interested in exploring these concepts more deeply, here are some resources that helped us:
-
“Building Microservices” by Sam Newman - The definitive guide that shaped our overall approach
-
“Domain-Driven Design Distilled” by Vaughn Vernon - Helped us apply DDD principles to our microservices architecture
-
“Designing Data-Intensive Applications” by Martin Kleppmann - Invaluable for understanding data consistency challenges
-
“The DevOps Handbook” by Gene Kim et al. - Guided our CI/CD implementation
-
“Monolith to Microservices” by Sam Newman - Provided patterns for establishing service boundaries
These resources provided the theoretical foundation that we translated into practical implementation in our EventFly project.